
I’ve been a loyal subscriber to HackerNewsletter for over seven years. But recently something strange happened: I read through 30+ recommendations and didn’t find a single one worth clicking. It wasn’t the newsletter’s fault – their curation is consistently good. But the the gap between what’s broadly interesting and what’s personally relevant to me has grown too wide.
That moment nudged me toward an idea I’d been toying with for a while - what if I could build my own tech digest, one that actually reflected my interests? And better yet, what if I used LLMs to help me do it? (Partly inspired by how consistently good AI News Digest has been).
So I built my own tech news curation system using LLMs. The results have been surprisingly effective, and the approach offers some interesting lessons about how to build reliable systems based on LLMs.
The Problem: Information Overload
Every morning, I used to start my day with the ritual of scanning Hacker News and various newsletters. Despite the time invested, I constantly felt I was:
- Missing important developments relevant to my interests
- Wasting time on clickbait or shallow content
- Getting stuck in filter bubbles that reinforced existing views
The core problem wasn’t that good content wasn’t available – it was that finding it among the noise had become a job in itself. And unlike recommendation algorithms optimizing for clicks, I wanted to optimize for long-term value and genuine insight.
Building a Better Filter: Evaluation-First AI
After reading Hamel Husain’s excellent piece on building evaluation systems for LLMs, I had decided to use his key insight: most AI projects fail because they lack robust evaluation systems. Instead of jumping straight to building the perfect news filter, I needed to start by defining what “good” looks like and systematically measuring it.
The approach I landed on was simple but powerful: build a system where every filtering decision is evaluated explicitly, and those evaluations feed back into improving the system.
The Judge System
At the heart of the system is the Judge System — an evaluation framework designed to close the loop between automated filtering and real human judgment. Instead of assuming the model would get things right on its own, I built a feedback mechanism to explicitly measure and improve its decisions over time.
Here’s how the process works:
- An LLM makes the initial filtering decision based on my stated interests.
- Each decision is logged as a structured trace with inputs, outputs, and metadata.
- I periodically review these traces, starting with a critique generated by a more powerful model.
- I edit and finalize that critique to better reflect my perspective — pass/fail, plus reasoning.
- The system tracks agreement rates between me and the filter over time to surface trends, edge cases, and areas for improvement.
What makes this approach effective is its simplicity: binary pass/fail decisions, backed by explicit reasoning I can review and refine. That clarity makes it easy to identify misalignments, iterate on prompts, and improve results — all without needing complex scoring systems or abstract rules.
The Judge UI
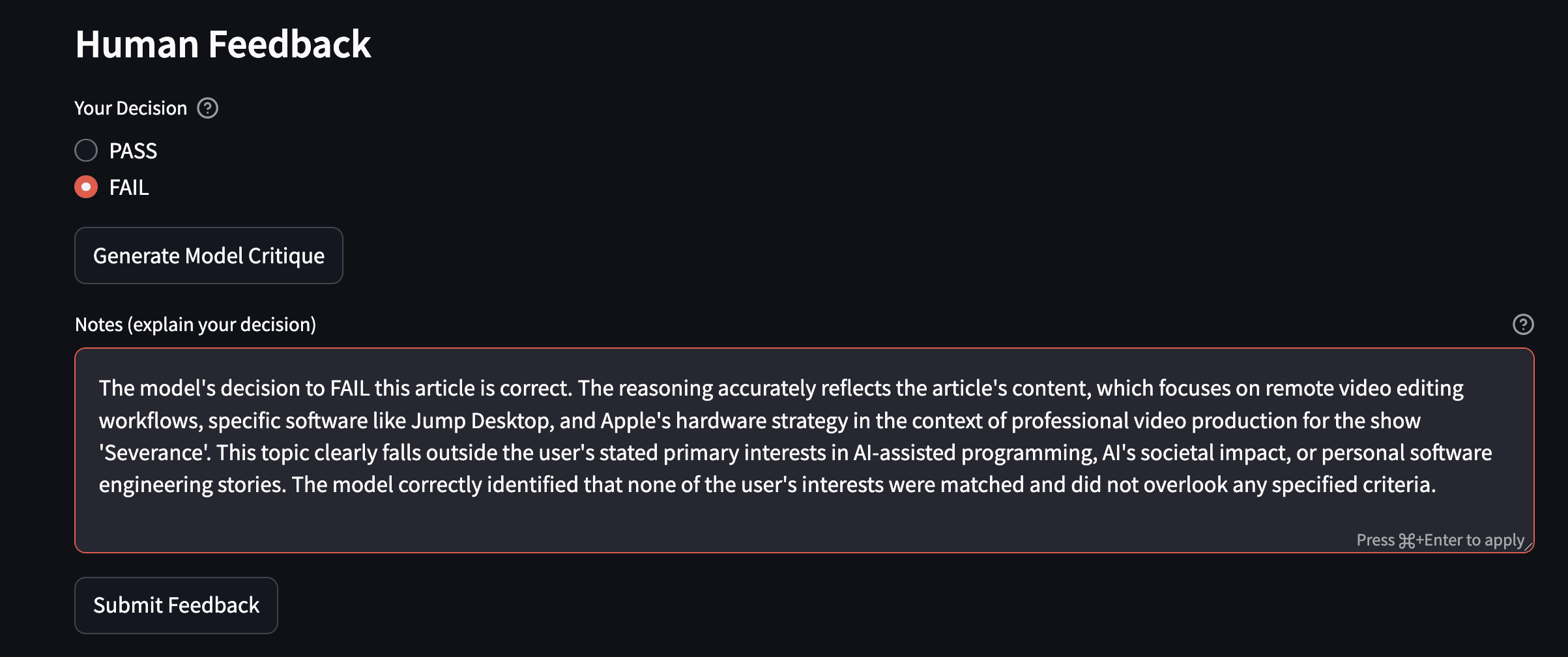
To make the evaluation easy, I built a lightweight Streamlit app to review and refine filtering decisions — the Judge UI.
When reviewing articles in the app, I can:
- View the original article alongside the LLM’s structured evaluation
- Generate an initial critique using a stronger model
- Edit that critique and log my final decision (pass/fail)
Over time, these examples get incorporated back into the filtering prompt, creating a continuous improvement loop. This feedback mechanism has been crucial - even a small amount of human feedback dramatically improves results.
The System Architecture
The complete system consists of several simple Python modules that work together:
- Data Collector (
hn_data_collector.py): Fetches articles from Hacker News via RSS and uses Jina.ai to extract content - LLM Gateway (
llm_gateway.py): Creates a unified interface for LLM interactions with structured outputs using Instructor - Content Filter (
content_filter.py): The LLM that makes initial decisions using a Pydantic model for consistency - Content Summarizer (
content_summarizer.py): Generates concise summaries of articles that pass the filter - Judge System (
judge_system.py): Manages feedback examples and evaluation metrics - Judge App (
judge_app.py): A Streamlit app that lets me review judgments and provide feedback - Digest Compiler (
digest_compiler.py): Formats everything into a readable digest
Using Structured Outputs for Reliability
One of the most important improvements I made was using Pydantic models (via Instructor) for structured LLM outputs. Here’s what a typical content filter response looks like:
1 | class ContentEvaluation(BaseModel): |
This structured approach has several advantages:
- Consistent outputs that can be easily parsed and stored
- Explicit fields for reasoning that make the LLM’s decision-making more transparent
- Simpler error handling and validation
Implementing the LLM Gateway
One of the other useful components I built was the LlmGateway class that handles all LLM interactions. It provides:
- A consistent interface for prompting and response parsing
- Automatic caching to reduce API costs and speed up testing
- Comprehensive logging of all interactions
- Structured output parsing via Instructor
This abstraction layer makes it easy to swap between different LLM providers and models. Currently, I’m using OpenRouter to access various models, but the system could easily work with OpenAI, Anthropic, or other providers.
Conclusion: Results, Lessons, and Future Directions
After running this system for about a month, the results have been transformative. My daily digest now contains just 2-3 high-quality articles (instead of sifting through 30+ iffy articles). The system catches 90% of what I would manually select and—perhaps more importantly—filters out 95%% of what I don’t want to see.
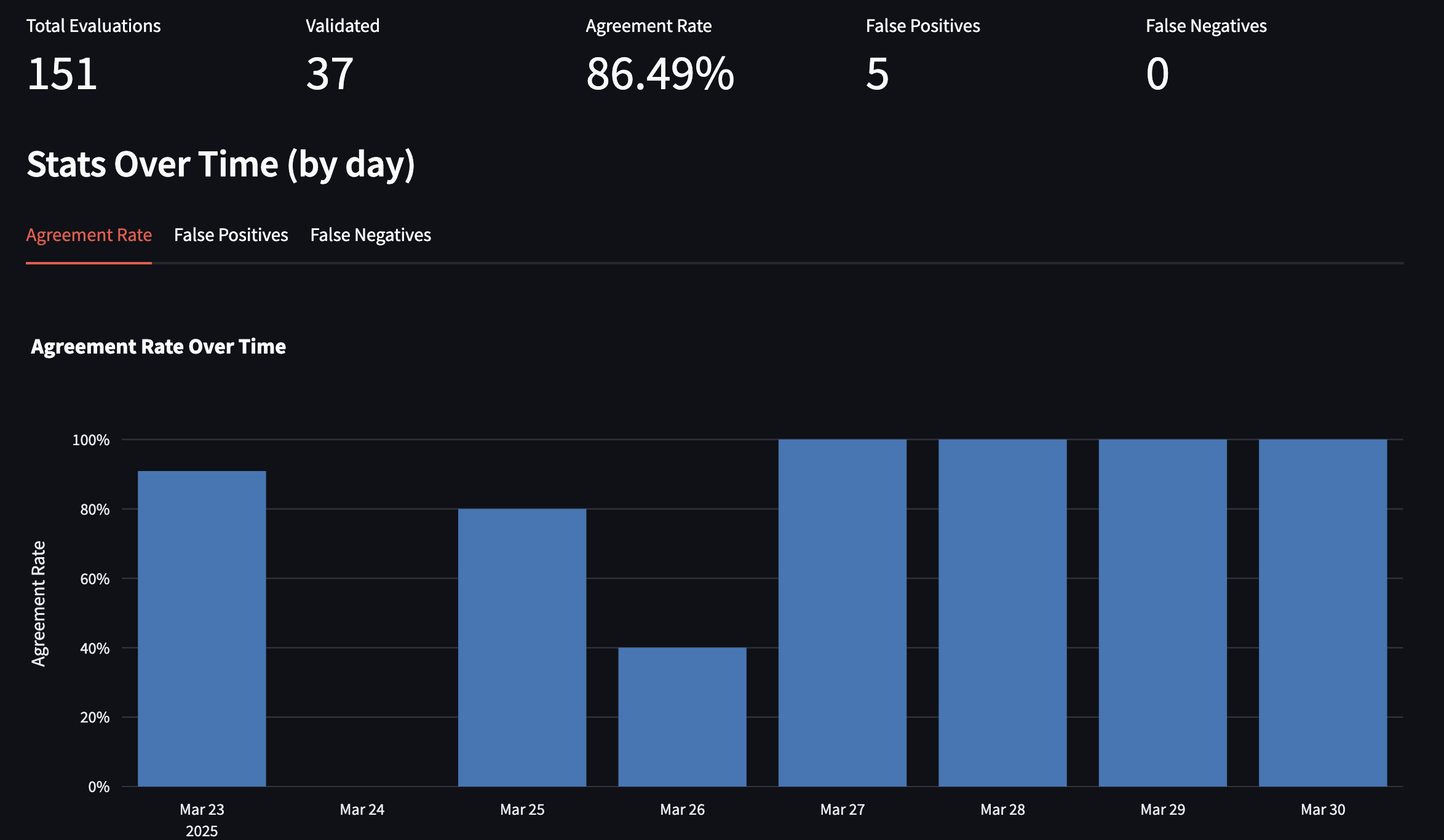
Building this system taught me several valuable lessons about working with LLMs:
- Evaluation is everything: Clear success metrics enable meaningful iteration
- Human feedback matters: Even minimal input can significantly boost alignment
- Binary decisions outperform scoring: Simple pass/fail decisions with explicit reasoning are more reliable han complex scoring systems
I’m actively exploring improvements: fine-tuning a model on my historical judgments, using RAG to surface only relevant past examples during evaluation, improving the summarization component, and expanding beyond Hacker News as a content source.
The full codebase is available at GitHub. If you’re overwhelmed by content and missing what really matters, building your own filter might be worth it. The tooling is ready — and the return is real.